Comment installer ZFS, le meilleur système de fichiers pour les serveurs
Nous connaissons tous et avons travaillé avec des systèmes de fichiers tels que NTFS sous Windows ou EXT4 sous Linux. Cependant, il existe d’autres systèmes de fichiers avec des caractéristiques, un fonctionnement et des performances différents. Aujourd’hui, dans RedesZone, nous allons parler en détail du système de fichiers ZFS , le meilleur système de fichiers pour les serveurs NAS où l’intégrité des fichiers est l’un des aspects les plus importants, sans oublier la protection des données contre les ransomwares ou le dysfonctionnement de l’un des les disques. Êtes-vous prêt à tout savoir sur ZFS ?
Qu’est-ce que ZFS et quelles fonctionnalités a-t-il ?
ZFS est un système de fichiers qui a été développé à l’origine par Sun Microsystems pour son système d’exploitation Solaris, le code source a été publié en 2005 dans le cadre du système d’exploitation OpenSolaris, mais cela a rendu ZFS utilisable dans d’autres systèmes d’exploitation et environnements. Au début, il y avait des problèmes avec les droits de ZFS, il a donc été décidé de faire différents «ports» pour l’adapter à différents systèmes d’exploitation sans avoir de problèmes de licence. En 2013, OpenZFS a été lancé sous l’égide du projet Umbrella, de telle sorte que ZFS puisse être utilisé sans problème dans les systèmes d’exploitation tels que Linux et FreeBSD, entre autres. A partir de ce moment, on peut retrouver le système de fichiers ZFS sous FreeBSD, NetBSD, Linux comme Debian ou Ubuntu entre autres.
Le système de fichiers ZFS est utilisé nativement dans les systèmes d’exploitation basés sur FreeBSD, tels que le populaire FreeNAS ou XigmaNAS, deux systèmes d’exploitation spécifiquement destinés aux serveurs NAS. Le fabricant QNAP avec son système d’exploitation QTS basé sur Linux utilise EXT4 depuis de nombreuses années, mais il a récemment publié un nouveau système d’exploitation appelé QuTS Hero qui permet d’utiliser le système de fichiers ZFS pour le stockage de masse, grâce à cette décision, nous pourra bénéficier de nombreuses améliorations dans l’intégrité des fichiers et dans leur protection contre d’éventuelles erreurs d’écriture.
Actuellement, le fabricant QNAP a des serveurs NAS qui ne prennent en charge que le système de fichiers ZFS, tous les NAS qui ont un «h» pour «Hero» dans leur modèle c’est parce qu’ils ont le système d’exploitation QuTS Hero, et donc nous avons le système de fichiers ZFS . Dans ces serveurs NAS nous avons une mémoire RAM de type ECC (avec correction d’erreur), cette caractéristique est indispensable lorsque nous utilisons ZFS car elle permet de détecter et de corriger les erreurs avant de l’écrire sur le disque. ZFS utilise intensivement la RAM comme premier cache, dans le but de fournir les meilleures performances en lecture et en écriture. De plus, si nous activons la déduplication, nous aurons également une consommation importante de mémoire RAM. Normalement, il est recommandé d’avoir 2 Go de RAM pour chaque 1 To de données que nous allons utiliser dans le pool, bien que cela puisse être moins. Pour cette raison, les NAS QNAP avec QuTS Hero sont capables de prendre en charge jusqu’à 128 Go de RAM ECC, dans le but de stocker une grande quantité d’informations dans ZFS et d’obtenir les meilleures performances possibles. Ces dernières semaines, QNAP a également lancé de nouveaux serveurs NAS qui nous permettent de choisir entre le système d’exploitation QTS normal ou QuTS Hero, de cette façon, l’utilisateur peut choisir entre EXT4 ou ZFS comme système de fichiers pour stocker toutes les données sur votre serveur, ces NAS ont également la possibilité d’installer de la RAM non ECC (pour EXT4) et de la RAM ECC si vous choisissez ZFS comme système de fichiers.
Avant de commencer à expliquer les principales fonctionnalités de ZFS, parlons de ses «limites». ZFS est conçu de telle manière que nous ne sommes jamais limités dans la vie réelle. ZFS vous permet de créer 2 48 instantanés de manière native, et vous permet également de créer jusqu’à 2 48 nombres de fichiers sur le système de fichiers. D’autres limites sont de 16 exaoctets pour la taille maximale d’un système de fichiers, et même de 16 exaoctets pour la taille maximale d’un fichier. La capacité de stockage maximale d’un pool est de 3 × 10 23 pétaoctets, nous aurons donc plus qu’assez d’espace au cas où nous en aurions besoin, en plus, nous pouvons avoir jusqu’à 2 64 disques dans un zpool, et 2 64 zpools dans un système .
Espaces de stockage virtuels (pools de stockage)
Dans ZFS, il existe ce que l’on appelle des «espaces de stockage virtuels», ou également appelés vdevs, qui sont essentiellement le périphérique de stockage, c’est-à-dire les disques durs ou SSD pour le stockage. Avec ZFS, nous n’avons pas les RAID typiques que l’on trouve dans les systèmes de fichiers comme EXT4, les RAID 0 typiques, RAID 1 ou RAID 5 entre autres, ils existent aussi ici, mais d’une manière différente.
Un « pool » peut être de plusieurs types, selon ce que l’on souhaite en termes de vitesse, d’espace de stockage et d’intégrité des données en cas de panne d’un ou plusieurs disques :
- Stripe : tous les disques sont mis dans un «pool» et les capacités des différents disques sont additionnées. En cas de panne de disque, nous perdrons toutes les informations. Ce type de pool s’apparente au RAID 0 mais permet d’y ajouter plusieurs disques.
- Miroir : tous les disques sont placés dans un «pool» et répliqués, la capacité maximale du pool sera la même que la capacité la plus faible d’un des disques. Tous les disques du miroir sont répliqués, par conséquent, nous ne perdrons des informations que si tous les disques du miroir sont cassés. Ce type de pool s’apparente à un RAID 1, mais il permet d’y intégrer plusieurs disques.
- RAID Z1 : tous les disques sont mis dans le pool. En supposant que tous les disques ont la même capacité, la capacité de tous les disques sauf un est ajoutée (si nous avons 3 disques de 4 To, l’espace de stockage effectif serait de 8 To). Il permet à l’un des disques d’être cassé et aux informations de rester intactes. Le fonctionnement s’apparente à un RAID 5 que nous connaissons tous. Un RAID Z1 doit avoir 3, 5 ou 9 disques dans chaque vdev, par conséquent, nous pouvons avoir un total de 9 disques dans un vdev et que, si l’un échoue, nous n’aurons pas de perte de données, en cas de défaillance d’un deuxième disque, nous perdra toutes les informations.
- RAID Z2 : tous les disques sont mis dans le pool. En supposant que tous les disques ont la même capacité, la capacité de tous les disques sauf celle de deux disques est ajoutée (si nous avons 4 disques de 4 To, l’espace de stockage effectif serait de 8 To). Il permet de casser deux des disques et les informations restent intactes. Le fonctionnement est similaire à un RAID 6 que nous connaissons tous. Un RAID Z2 doit avoir 4, 6 ou 10 disques dans chaque vdev, par conséquent, nous pouvons avoir un total de 10 disques dans un vdev et que, si deux échouent, nous n’aurons pas de perte de données, en cas de défaillance d’un troisième disque, nous perdra toutes les informations.
- RAID Z3 : tous les disques sont mis dans le pool. En supposant que tous les disques aient la même capacité, la capacité de tous les disques sauf trois est ajoutée (si nous avons 5 disques de 4 To, l’espace de stockage effectif serait de 8 To). Il permet à trois des disques d’être cassés et aux informations de rester intactes. Un RAID Z3 doit avoir 5, 7 ou 11 disques dans chaque vdev, par conséquent, nous pouvons avoir un total de 1 disques dans un vdev et que, si trois échouent, nous n’aurons pas de perte de données, en cas de défaillance d’un quatrième disque, nous perdra toutes les informations.
D’autres configurations que nous pouvons effectuer avec ZFS est de définir un disque comme » Hot Spare «, ou aussi connu comme » Spare «, de sorte qu’en cas de panne de disque, ce disque de sauvegarde se mettra automatiquement en marche et démarrera le processus de sauvegarde réargenture (régénération des données à l’aide de ce nouveau disque que nous venons d’introduire dans le pool). Nous avons également la possibilité de définir un disque comme un » cache «, ce qui signifie essentiellement activer le L2ARC et avoir des performances plus élevées, c’est idéal si nous l’utilisons avec un SSD rapide, de manière à augmenter les performances globales de le système, si vous allez Si vous utilisez un disque dur normal, vous ne remarquerez aucune amélioration et pouvez même détériorer les performances. Enfin, nous avons aussi la possibilité de définir un disque comme « LOG»(SLOG ZFS Intent Log) pour stocker les journaux d’écriture qui auraient dû se produire, ceci est utile en cas de panne de courant.
ZFS utilise le cache que nous avons commenté précédemment pour accélérer considérablement les transferts de données, à la fois en lecture et en écriture. De plus, nous améliorerons non seulement la lecture et l’écriture séquentielles mais également la lecture et l’écriture aléatoires.
Systèmes de fichiers légers (ensemble de données)
Les ensembles de données sont vraiment les systèmes de fichiers ZFS, c’est ce qui se trouve à l’intérieur d’un espace de stockage ZFS. Pour créer un dataset il est indispensable d’avoir créé un «pool» auparavant, sinon il n’est pas possible de le créer. Il existe deux types de jeux de données différents :
- Système de fichiers : c’est le type de jeu de données par défaut, c’est celui utilisé pour stocker les fichiers, dossiers, etc. Vous pouvez définir le point de montage directement, sans modifier le fstab Linux typique.
- ZVOL : c’est un ensemble de données qui représente un appareil par blocs, on peut aussi le retrouver dans les différents systèmes d’exploitation comme « Volume ». Cet ensemble de données vous permet de créer un périphérique bloc, puis de le formater avec des systèmes de fichiers tels que EXT4.
Certaines des caractéristiques les plus importantes d’un ensemble de données (système de fichiers) sont qu’il vous permet de configurer des quotas, un quota de disque réservé, une gestion des autorisations avec des listes de contrôle d’accès avancées (ACL) et autorise même des fonctionnalités très avancées telles que les suivantes :
- Déduplication (déduplication) – La déduplication est une technique de suppression des doublons de données en double. On ne pourrait pas l’appeler «compresser», mais il est vrai que, si on fait de la déduplication, la taille finale d’un ensemble de données est nettement plus petite. Cette technique est utilisée pour optimiser le stockage des données sur disque. ZFS effectue la déduplication de manière native, il est donc très efficace, mais pour qu’il fonctionne correctement, il a besoin d’une grande quantité de RAM : pour chaque 1 To de jeu de données dédupliqué, environ 16 Go de RAM sont nécessaires . Considérant que l’espace de stockage (disques durs) est aujourd’hui beaucoup moins cher que la RAM, il est conseillé de ne pas utiliser la déduplication, sauf si vous savez ce que vous faites.
- Compression: nativement ZFS permet l’utilisation de différents algorithmes de compression, afin d’économiser de l’espace de stockage dans le dataset et donc dans le pool. L’algorithme de compression LZ4 est actuellement le standard et le plus recommandé dans la plupart des situations, d’autres comme LBJB peuvent également être utilisés, et même GZIP avec différents niveaux de compression. Cependant, très bientôt, nous verrons ZSTD qui est un nouvel algorithme de compression pour ZFS. ZSTD est un algorithme de compression général moderne et hautes performances, créé par la même personne que LZ4, il vise à fournir des niveaux de compression similaires à GZIP, mais avec de meilleures performances. Une autre caractéristique intéressante de ZSTD est qu’il vous permet de sélectionner différents niveaux de compression/performance pour répondre aux besoins des administrateurs.
- Instantáneas (Snapshots) : las instantáneas nos permiten guardar una «foto» del estado del sistema de archivos en un determinado momento, con el objetivo de proteger la información si sufrimos el ataque de un ransomware, o que directamente eliminamos un archivo cuando no deberíamos haberlo Fait. Bien que des fabricants comme QNAP ou Synology aient des instantanés et utilisent EXT4, les instantanés ZFS sont natifs, ils fonctionnent donc beaucoup plus efficacement. ZFS nous permet de visualiser les données de ces instantanés sans les annuler, en annulant toutes les modifications, et même de «cloner» ces instantanés que nous avons pris. Ce «clone» vous permet d’avoir deux systèmes de fichiers indépendants qui peuvent être créés en partageant un ensemble commun de blocs. Le nombre d’instantanés que nous pouvons prendre avec ZFS est de 2 48, c’est-à-dire que vous pourriez dire que nous avons des instantanés illimités.
ZFS n’écrase pas les données en raison du modèle de copie sur écriture dont nous parlerons plus tard, donc prendre un instantané signifie simplement ne pas libérer les blocs utilisés par les anciennes versions. Les instantanés sont pris très rapidement et sont vraiment efficaces du point de vue de l’espace, ils ne prennent rien sauf si vous modifiez une donnée qui a été «instantanée». C’est-à-dire qu’il n’y a pas de duplication de données, l’instantané et les données de production sont partagés, ce n’est qu’en les modifiant lorsque l’occupation commence à augmenter.
Auto-guérison
L’une des caractéristiques les plus importantes de ZFS est l’auto-réparation.Nous avons précédemment mentionné qu’il existe des pools de miroirs et également RAID-Z, avec une parité simple, double ou triple. Un aspect très important est que ZFS n’a pas le défaut «write-hole», cela peut se produire lorsqu’une panne de courant se produit pendant l’écriture, cela rend impossible de déterminer quels blocs de données ou blocs de parité ont été écrits sur les disques et lesquels ne sont pas. Dans cette situation d’erreur catastrophique, les données de parité ne correspondent pas au reste des données dans l’espace de stockage, de plus, il n’est pas possible de savoir quelles données sont fausses : les données de parité, ou les données de bloc.
Toutes les données dans ZFS sont hachées avant leur écriture dans le pool, l’algorithme de hachage peut être configuré lors de la création de l’ensemble de données. Une fois les données écrites, le hachage est vérifié pour vérifier qu’il a été écrit correctement et qu’il n’y a eu aucun problème d’écriture. ZFS facilite la vérification de l’intégrité des données en utilisant ces données hachées. Si les données ne correspondent pas au hachage, ce qui est fait est de rechercher le miroir ou de calculer les données via le système de parité (RAID-Z) pour procéder à sa vérification au niveau du hachage. Si les données de hachage sont les mêmes, procédez à la correction des données dans le bloc. Tout cela se fait de manière entièrement automatique.
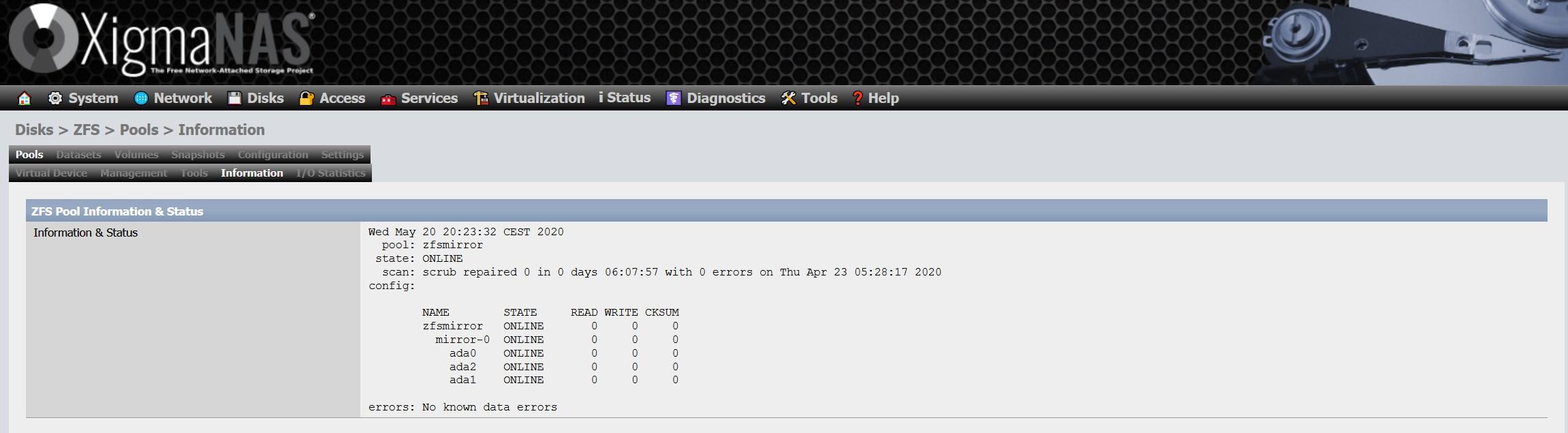
Copie sur écriture
ZFS utilise une architecture de copie sur écriture, grâce à cela, nous évitons les problèmes dérivés du trou d’écriture que nous avons expliqué précédemment. CoW est l’une des principales fonctionnalités de ZFS. La façon dont cela fonctionne est que tous les pointeurs de bloc dans un système de fichiers contiennent une somme de contrôle, qui est vérifiée en lisant le bloc. Les blocs contenant des données actives ne sont jamais écrasés, ce qui est fait est de réserver un nouveau bloc et les données modifiées y sont écrites directement. Pour le rendre plus rapide et plus efficace, plusieurs mises à jour sont généralement ajoutées pour effectuer des transactions ultérieurement, et même un ZIL (ZFS Intent Log) est utilisé.
L’inconvénient est que cela produit une fragmentation élevée dans les pools et qu’il n’y a actuellement aucune possibilité d’effectuer une défragmentation. Si votre pool est composé de SSD, vous ne remarquerez pas beaucoup de perte de performances du fait de la nature même des SSD, mais si vous utilisez des disques durs, vous pourrez le constater. Dans notre cas, nous avons une fragmentation supérieure à 25% après plusieurs années d’utilisation :
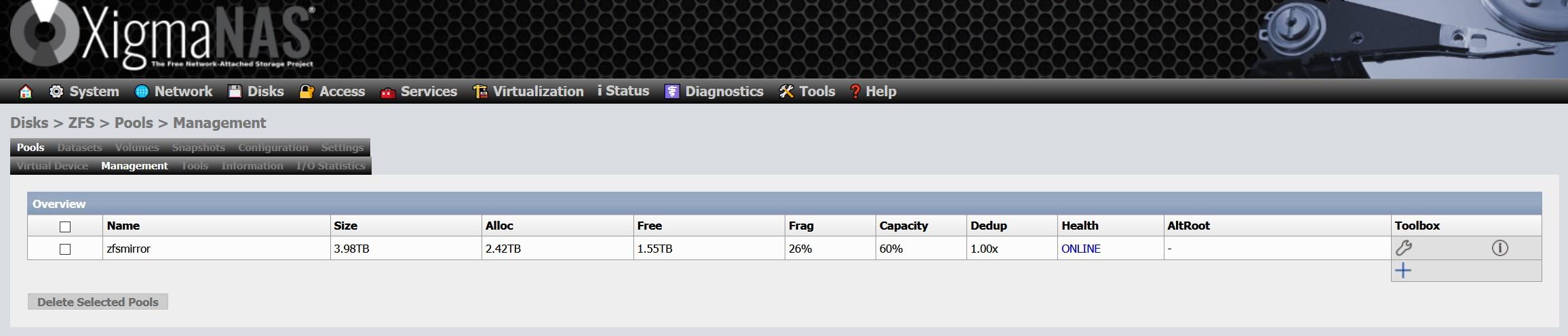
Le seul moyen de défragmenter le pool est de copier les données sur un autre support, de supprimer le pool et de le recréer. C’est-à-dire qu’il n’y a aucun moyen de défragmenter un pool dans ZFS, du moins pour le moment.
Striping dynamique
ZFS distribue les données que nous écrivons de manière dynamique sur tous les périphériques virtuels (vdev), afin de maximiser les performances. La décision de l’emplacement des données est prise au moment de la rédaction. Cela améliore considérablement les pools miroir et RAID-Z, et élimine également efficacement le problème de trou d’écriture que nous avons vu précédemment. Une autre caractéristique intéressante est que ZFS utilise des blocs de taille variable jusqu’à 128K, l’administrateur peut configurer la taille de bloc maximale utilisée, idéale pour s’adapter aux besoins de ce qui va écrire dans le pool, mais elle peut être adaptée automatiquement. Dans le cas de l’utilisation de la compression, ces tailles de blocs variables sont utilisées pour le rendre beaucoup plus efficace en termes d’espace.
Fonctionnalités et améliorations d’OpenZFS 2.0
OpenZFS 2.0 est maintenant une réalité, la dernière version de ce système de fichiers haute performance et à haute intégrité des données a été mise à jour avec des nouvelles très intéressantes. La première chose que nous devons indiquer est qu’OpenZFS 2.0 est compatible avec FreeBSD 12 et plus, et il est également compatible avec le noyau Linux entre les versions 3.10 et 5.9, par conséquent, nous aurons une grande compatibilité pour presser toutes ses nouvelles.
Certaines des nombreuses améliorations qui ont été incorporées dans ce système de fichiers sont les suivantes :
- Réargenture séquentielle des données : La fonction de réargenture séquentielle vous permet de reconstruire un miroir vdev en très peu de temps par rapport à la réargenture traditionnelle. La redondance complète est restaurée aussi rapidement que possible, puis le pool est automatiquement nettoyé pour vérifier toutes les sommes de contrôle.
- L2ARC persistant : Cette fonction rend le périphérique L2ARC pour le cache de données persistant, même si nous redémarrons l’ordinateur, cela élimine le temps de préparation du cache habituel dont nous avons normalement besoin après l’importation du groupe.
- Compression ZST intégrée : dans cette nouvelle version de ZFS, nous avons l’algorithme de compression Zstandard, un algorithme de compression moderne et performant, et c’est un algorithme de compression «général», il fonctionne donc très bien quelles que soient les données que nous sommes va compresser. Cet algorithme fournit des niveaux de compression similaires ou meilleurs que GZIP, mais avec de bien meilleures performances. Nous pouvons sélectionner le niveau de compression pour permettre d’équilibrer performances/compression en fonction de nos besoins.
- Incorporation de « Streams expurgés » en réception et en envoi, cette fonctionnalité permet d’envoyer des sous-ensembles de données vers un système de destination. Il permet aux utilisateurs d’économiser de l’espace en ne reproduisant pas les données sans importance, et nous pouvons même choisir d’exclure des informations.
D’autres changements introduits dans cette nouvelle version sont liés aux commandes, de nouvelles commandes ont été ajoutées, et certaines que nous avions déjà ont été modifiées, pour les adapter aux nouvelles fonctionnalités de ZFS. Si vous voulez connaître en détail les changements dans les commandes ZFSNous vous recommandons de visiter le GitHub officiel. D’autres améliorations intégrées incluent la prise en charge de la pré-allocation d’espace, les pages de manuel officielles du didacticiel ZFS ont été réorganisées, un module PAM a été activé pour charger automatiquement les clés de chiffrement ZFS, et bien plus encore. Enfin, les performances ont été grandement améliorées, et maintenant la suppression des clones des snapshots est beaucoup plus rapide avec zfs destroy, l’envoi/réception de petits enregistrements est également beaucoup plus rapide, l’évolutivité de la ressource a été améliorée zfs partagé, mémoire gestion et ARC est beaucoup plus efficace, les performances AES-GCM ont également été améliorées pour protéger nos données avec une couche de cryptage.
Comment installer et lancer ZFS
ZFS est installé sur les systèmes d’exploitation basés sur FreeBSD, tels que XigmaNAS ou FreeNAS. Le système de fichiers par défaut sur ces systèmes d’exploitation est UFS, mais nous avons la possibilité d’utiliser ZFS comme système de fichiers système. Cependant, il est préférable d’utiliser ZFS comme système de fichiers du pool de stockage où nous allons avoir chacun de nos fichiers, c’est là que nous pouvons vraiment en tirer le meilleur parti. Dans ces systèmes d’exploitation orientés NAS, nous n’aurons à exécuter aucune commande puisque tout se fait avec l’interface utilisateur graphique, sans avoir à toucher à autre chose. D’autres systèmes d’exploitation tels que Debian, Ubuntu, Linux Mint et autres, nous devrons installer ZFS manuellement.
Ensuite, nous allons vous montrer comment configurer et lancer ZFS sur un système d’exploitation XigmaNAS (basé sur FreeBSD), la procédure est similaire à FreeNAS puisque nous utilisons le même système de fichiers. Nous vous apprendrons également à l’installer sur des systèmes d’exploitation comme Debian, bien qu’ici, nous devrons tout faire via la console de commande.
Configuration et démarrage ZFS sur XigmaNAS
Pour ce tutoriel, nous avons utilisé VMware pour virtualiser XigmaNAS, et nous avons créé un total de 6 disques virtuels. Le premier disque virtuel d’une capacité de 20 Go est destiné à installer le système d’exploitation lui-même, et il est au format UFS qui est natif de FreeBSD. Les 5 autres disques de 100 Go chacun sont orientés vers l’espace de stockage du système de fichiers ZFS et seront formatés en ZFS.
Étape 1 : Formatez les disques au format ZFS pour les ajouter à un pool.
La première étape consiste à formater les disques au format ZFS pour les ajouter à un pool, pour cela, on va dans « Disques/Administration ».
Dans ce menu, nous allons dans l’onglet «Options HDD» et cliquons sur «Importer des disques – Importer», pour importer tous les disques que nous avons configurés sur le serveur.
Tous les disques non formatés apparaîtront, car nous venons de les ajouter, mais le disque du système d’exploitation apparaîtra également au format UFS.
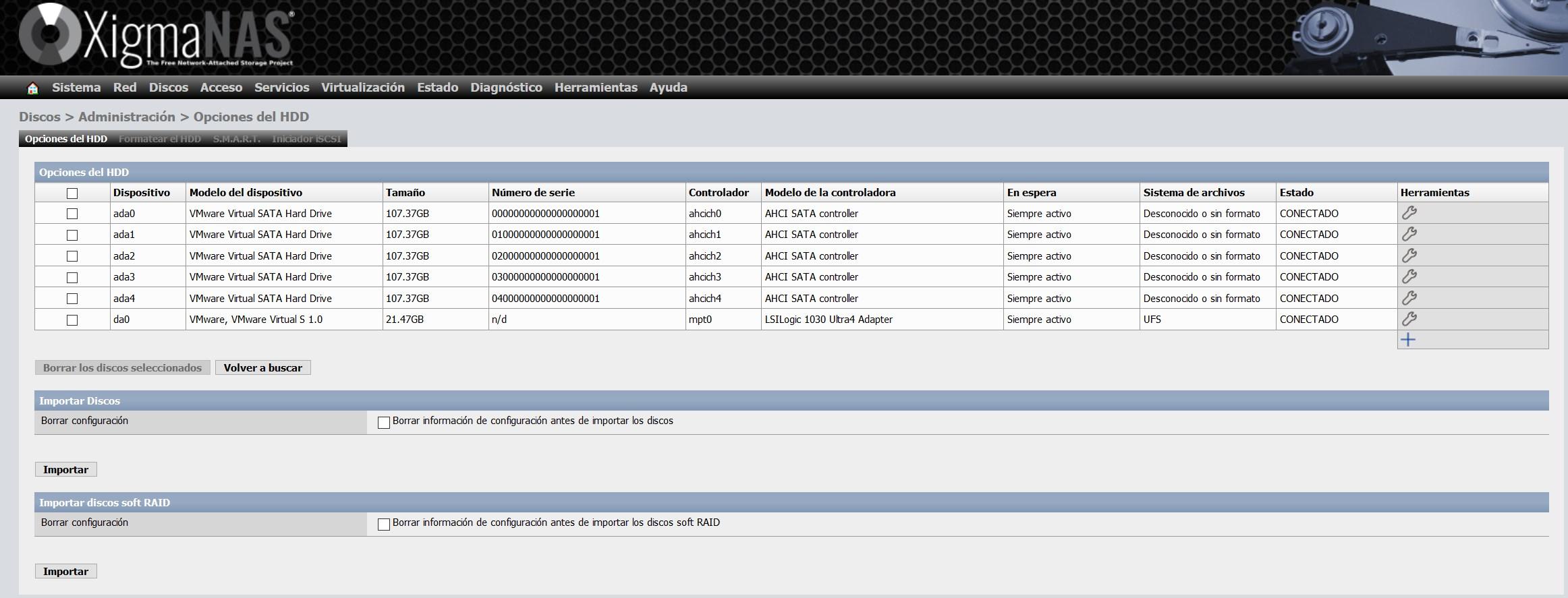
Dans l’onglet » Formater le disque dur «, nous sélectionnons tous les disques et sélectionnons » Système de fichiers : stockage ZFS dans le groupe de périphériques (Pool) «.
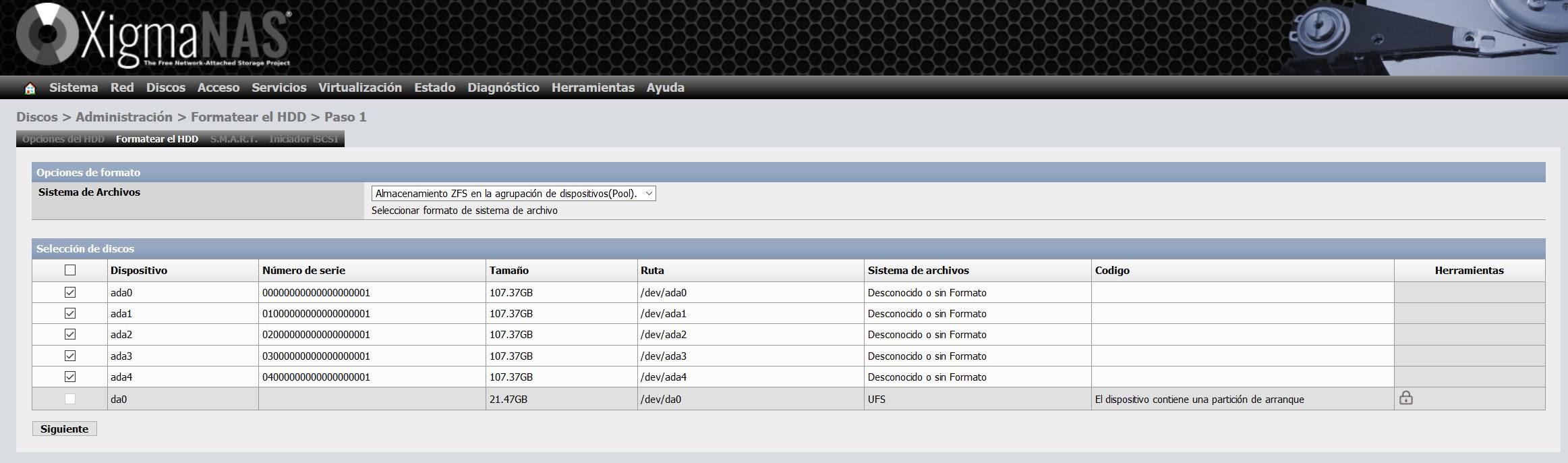
Dans l’assistant de configuration pour le formater, nous pouvons leur donner un nom de volume, comme vous pouvez le voir ci-dessous :

Nous cliquons sur suivant et nous aurons déjà formaté tous les disques au format ZFS, prêts à les ajouter à un pool ZFS.
Étape 2 : Créez l’appliance virtuelle vdev ZFS
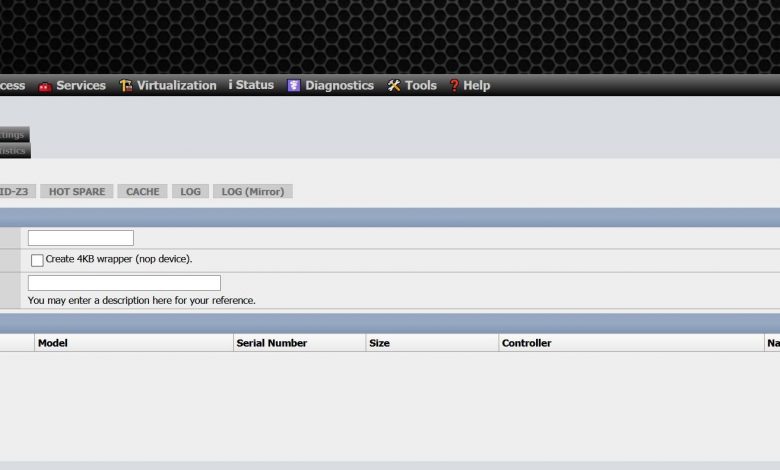
Maintenant, nous devons aller dans «Disques / ZFS» et nous accéderons à la section «Pools de périphériques (pools)» dans la partie «Périphérique virtuel». Dans cette section, nous cliquons sur le «+» que nous avons à droite.

Ici, ce que nous devrons faire, c’est sélectionner tous les disques que nous voulons intégrer au vdev, en fonction du nombre de disques que nous ajoutons, nous aurons la possibilité de configurer un «Stripe», «Mirror» et les différents RAIDZ. Nous avons choisi les cinq disques, nous pourrons donc créer les cinq types.
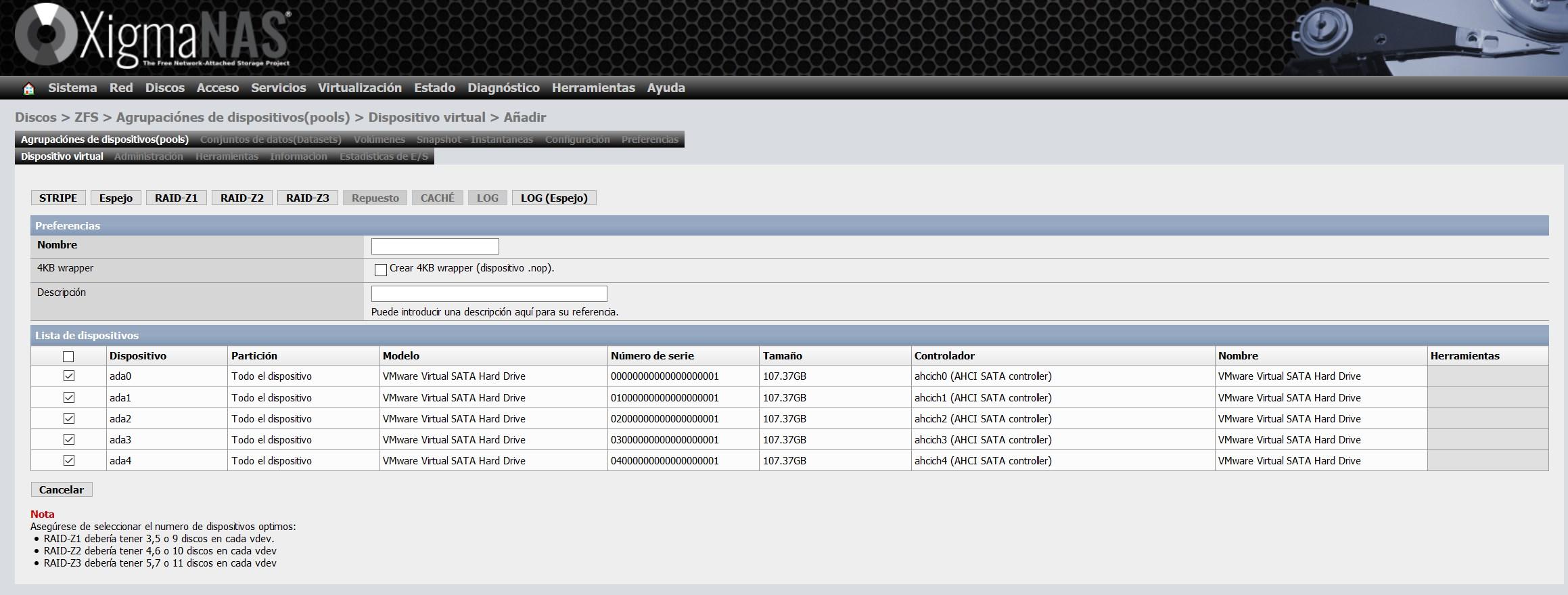
Nous avons choisi l’option « Miroir », également appelée « Miroir ». Avec cette option, nous aurons exactement les mêmes informations sur les cinq disques.
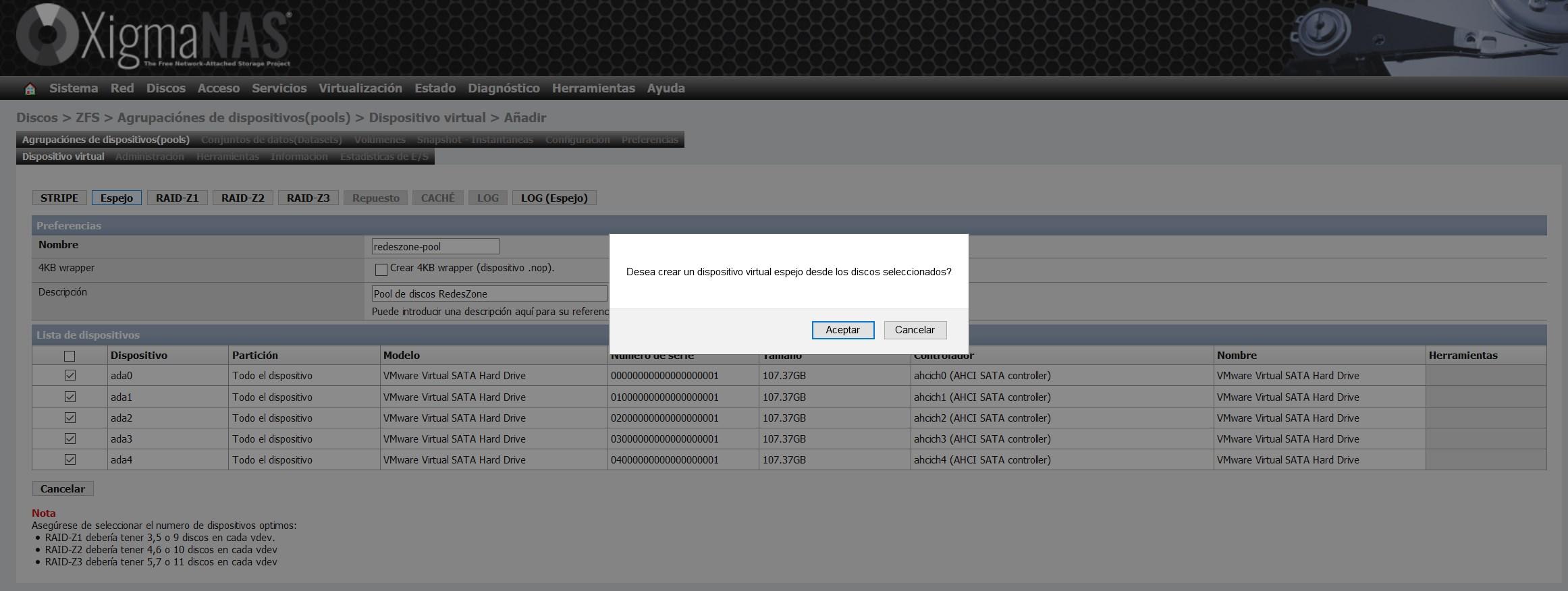
Une fois que nous avons créé le périphérique virtuel, il apparaîtra dans la liste des périphériques virtuels, comme vous pouvez le voir ici :
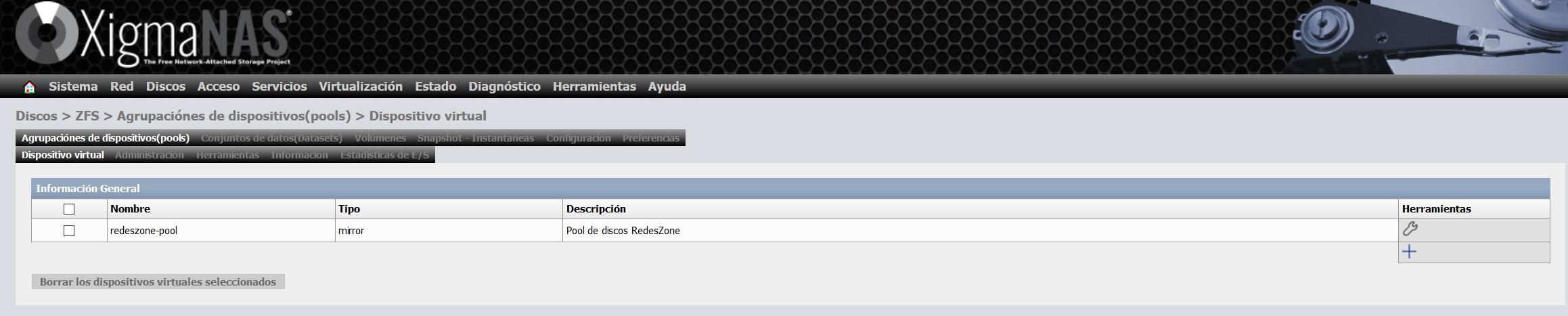
Étape 3 : Configurer le pool et lui donner un nom
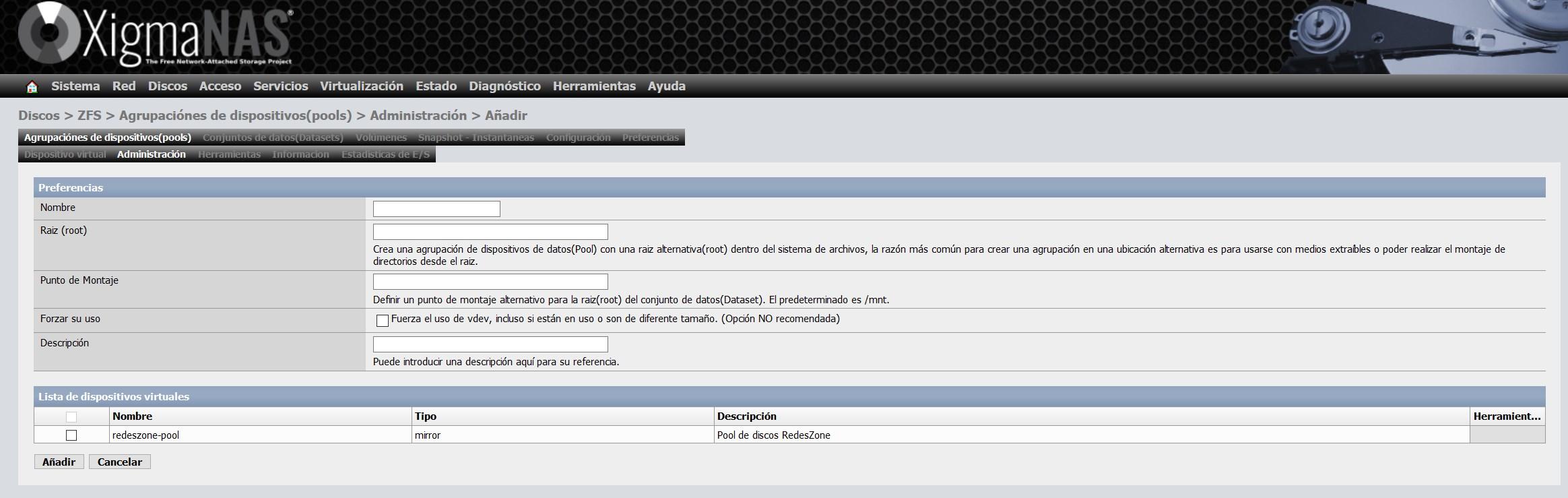
Une fois le vdev créé, il faut aller dans «Administration», et cliquer sur «+» pour formater ce vdev et pouvoir l’utiliser plus tard avec un Dataset ou un Volume.

Nous devons lui donner un nom, et nous pouvons également définir le point de montage que nous voulons, le point de montage par défaut est /mnt.
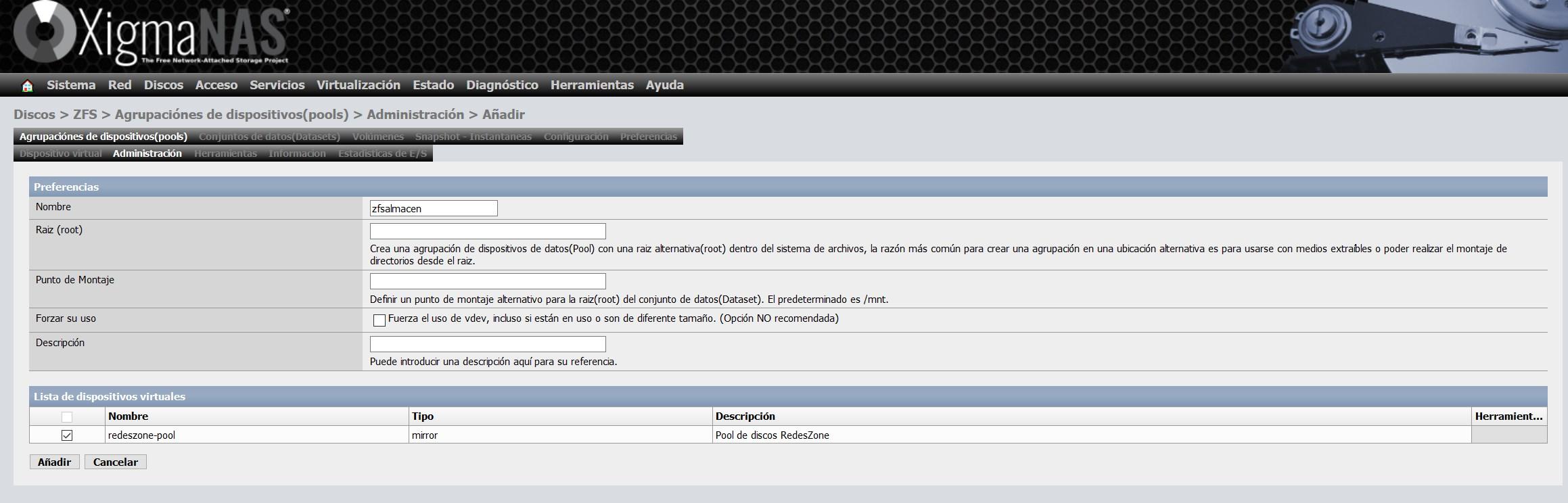
Nous allons lui donner le nom de zfsalmacen et choisir le vdev que nous avons créé précédemment, comme vous pouvez le voir ici :
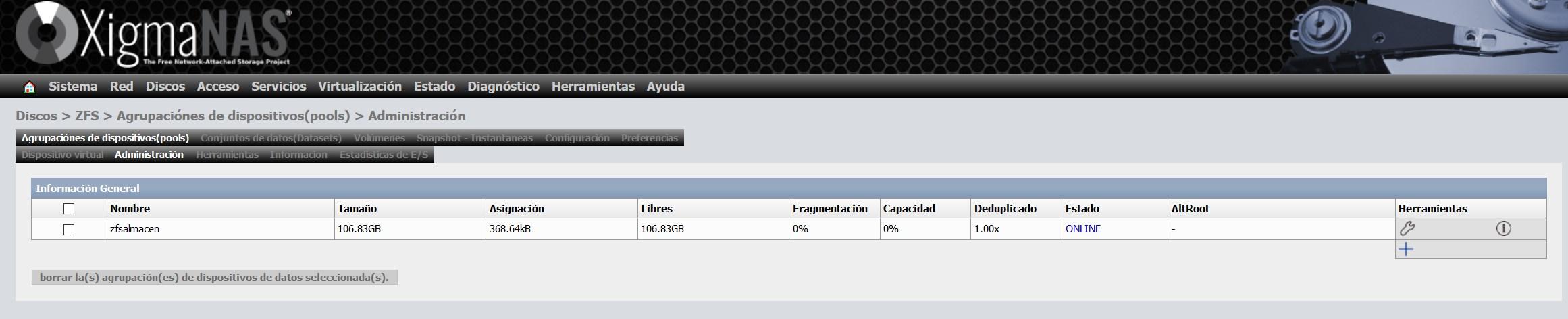
Une fois que nous l’avons créé, la taille totale, la taille libre, la fragmentation, etc. apparaîtront.
Une section très importante de XigmaNAS est la section «Outils», ici nous aurons différents assistants de configuration pour effectuer différentes actions, nous pouvons faire tout cela manuellement à l’aide de commandes, mais avec cette interface utilisateur graphique, nous pouvons le faire en quelques clics. Ce qui nous permet d’effectuer XigmaNAS est tout ce qui suit :
- Mettre à jour le noyau ZFS et ajouter la prise en charge de nouvelles fonctionnalités au pool de périphériques
- Ajouter un appareil de rechange au pool d’appareils de données (Pool)
- Ajouter un périphérique pour CACHE au pool de périphériques de données (Pool)
- Ajouter un périphérique pour LOG au pool de périphériques de données (Pool)
- Connecter un appareil pour les données
- Déconnecter un périphérique de données d’un miroir
- Afficher l’historique des commandes ZFS
- Éliminer les erreurs de périphérique
- Supprimer la balise ZFS de l’appareil
- Supprime un pool de périphériques de données (Pool).
- Exporter un pool ZFS à partir du système
- Générer un identifiant unique pour le pool d’appareils
- Répertorier ou importer des pools d’appareils
- Mettre l’album hors ligne
- Mettre un appareil en ligne
- Remplacer un appareil
- Nettoyer le pool d’appareils
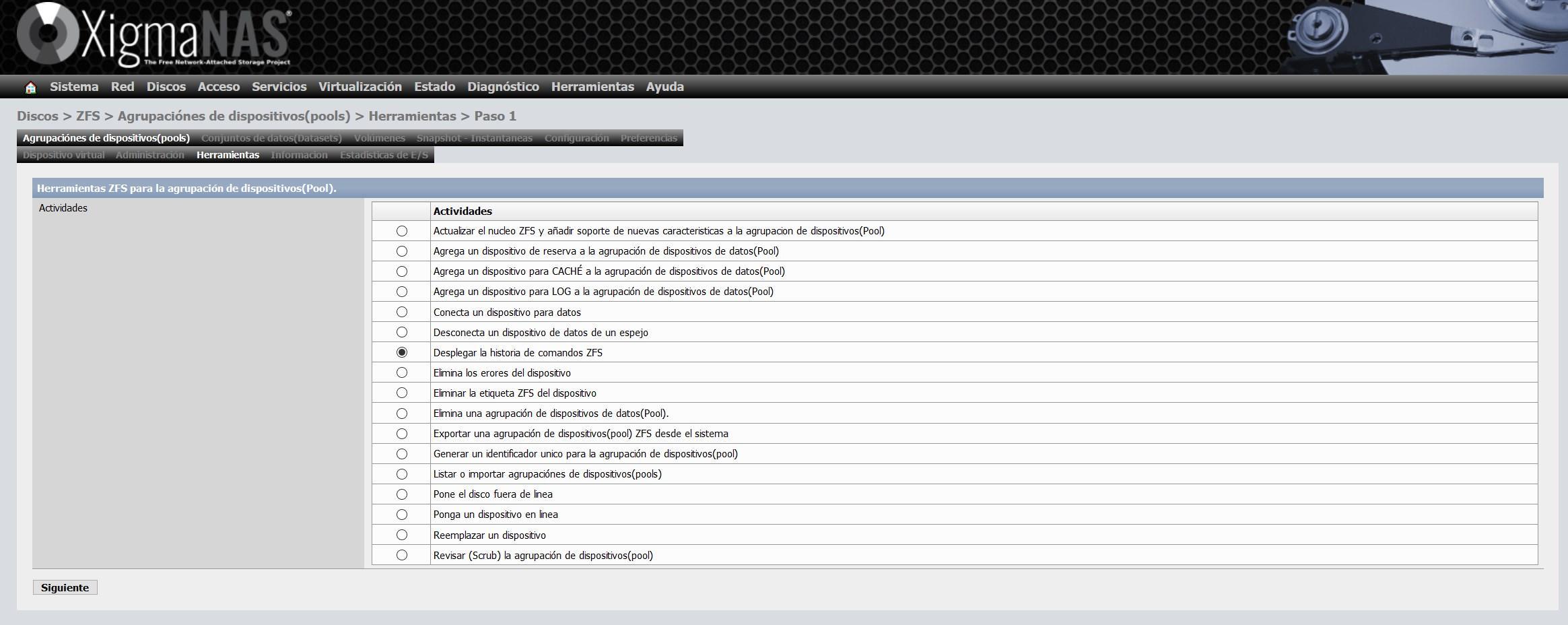
Dans la section «Informations», nous pouvons voir l’état général du ZFS, le type de vdev choisi et aussi tous les disques que nous avons dans le pool. Un détail important est qu’il est possible que nous n’ayons pas mis à jour le ZFS vers la dernière version sur les disques eux-mêmes, si nous recevons cet avertissement, nous devrons effectuer une mise à jour très simple.
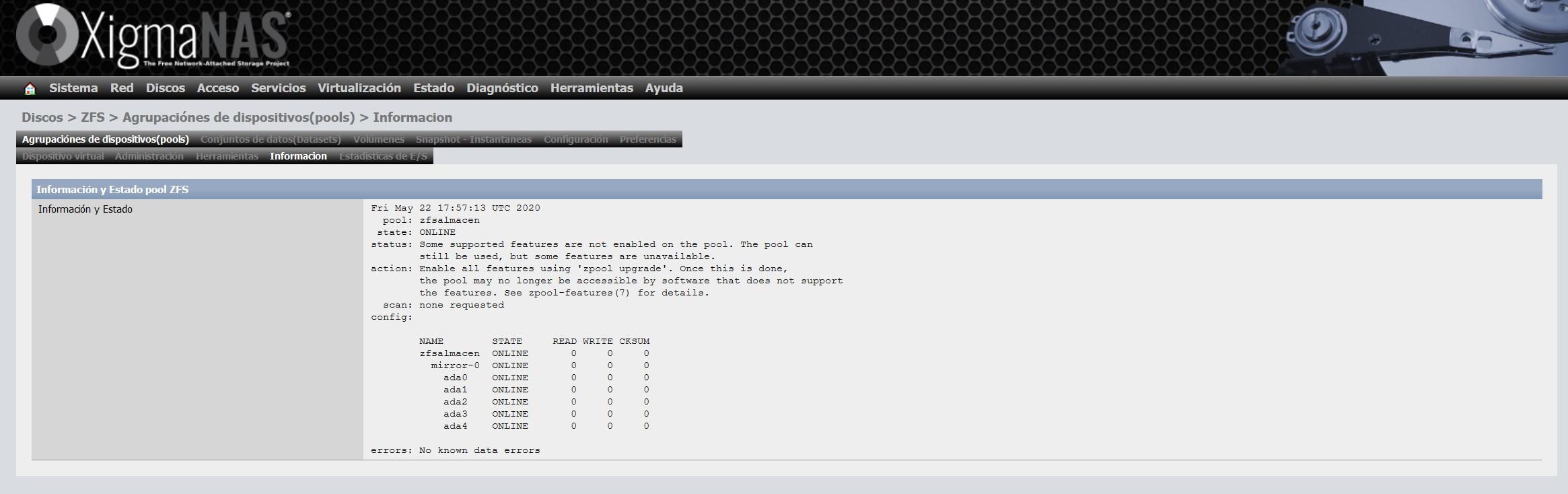
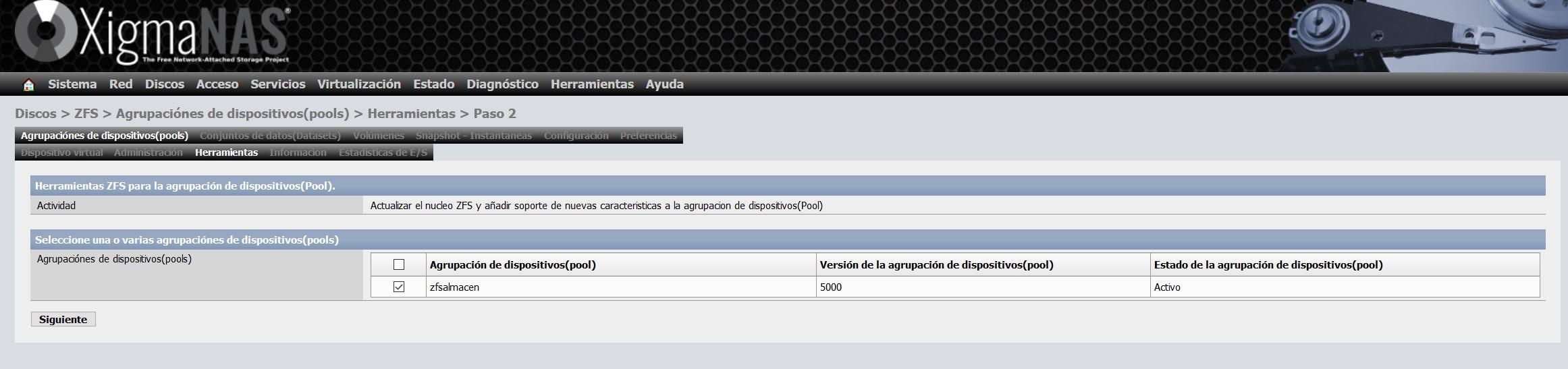
Pour le mettre à jour, nous allons dans la section «outils» et sélectionnons l’option «Mettre à jour le noyau ZFS et ajouter le support des nouvelles fonctionnalités au groupe de périphériques (Pool)» et poursuivons l’assistant pour le mettre à jour.
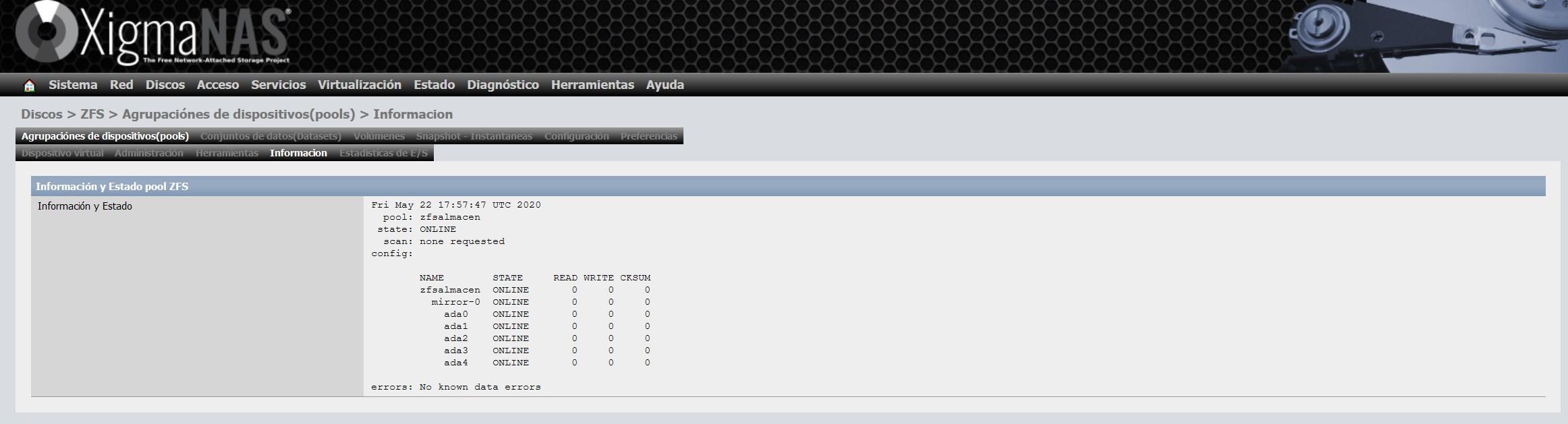
Dès que nous l’aurons mis à jour, nous ne recevrons aucun avertissement, comme vous pouvez le voir ici :
Étape 4 : Créer l’ensemble de données ou le volume
Créer un dataset est très simple, on va dans « Dataset (dataset) » et on clique sur la touche « + » :

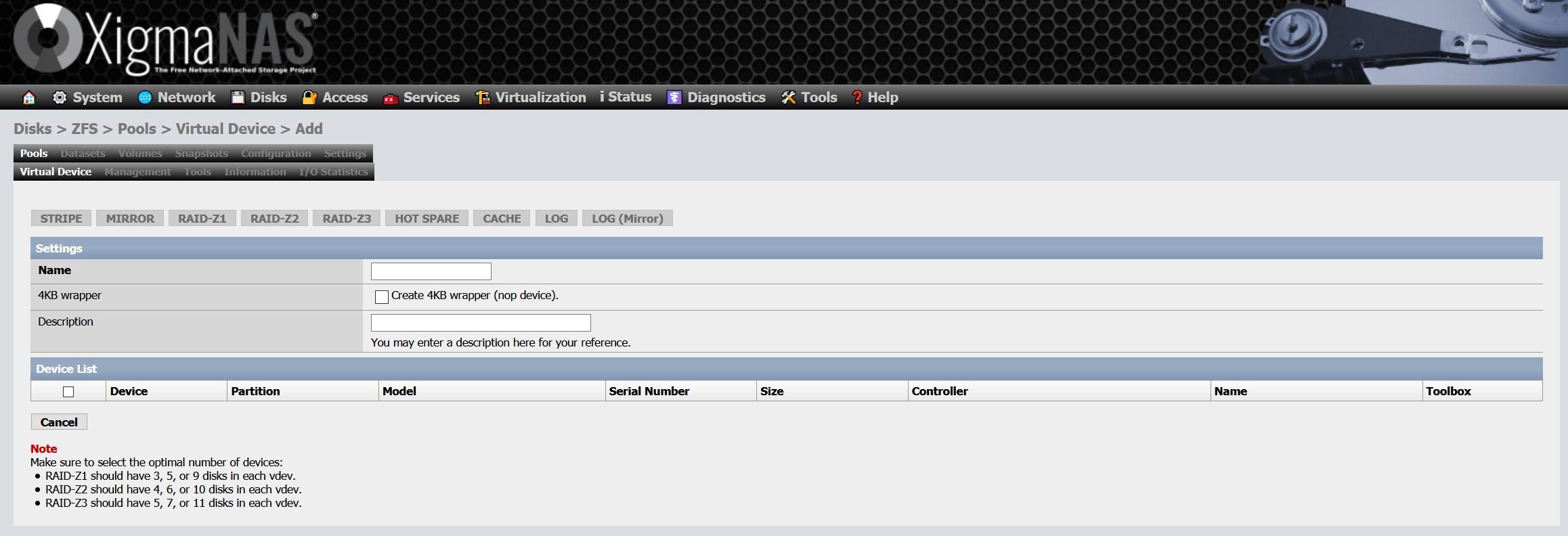
Dans la configuration du jeu de données, nous devons choisir un nom, ainsi que le pool dans lequel nous voulons créer le jeu de données. Nous n’avons créé qu’un seul pool, il n’y a donc pas de perte. C’est ici que nous pouvons configurer la compression en temps réel, la déduplication, la synchronisation, les listes de contrôle d’accès et bien d’autres paramètres avancés.
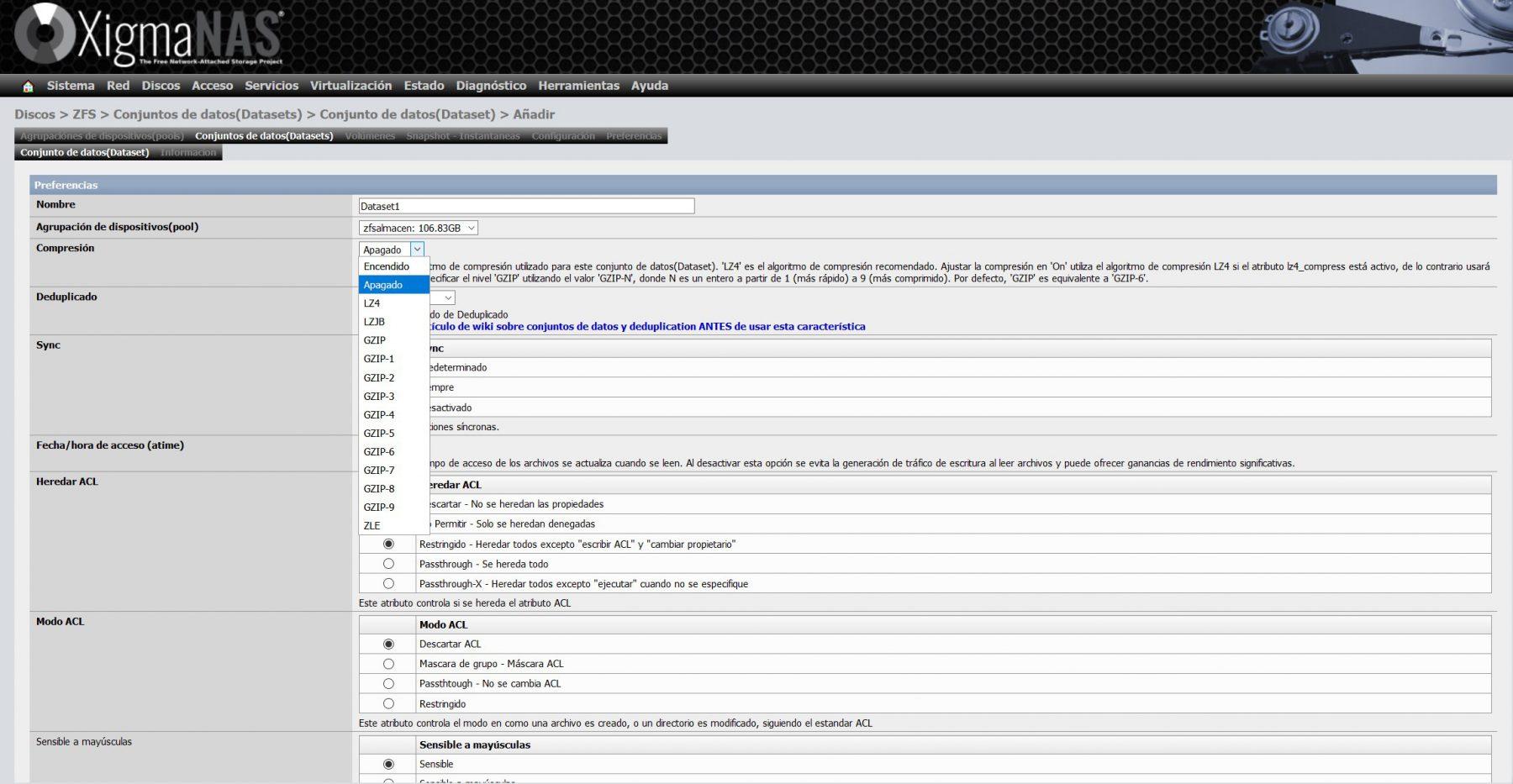
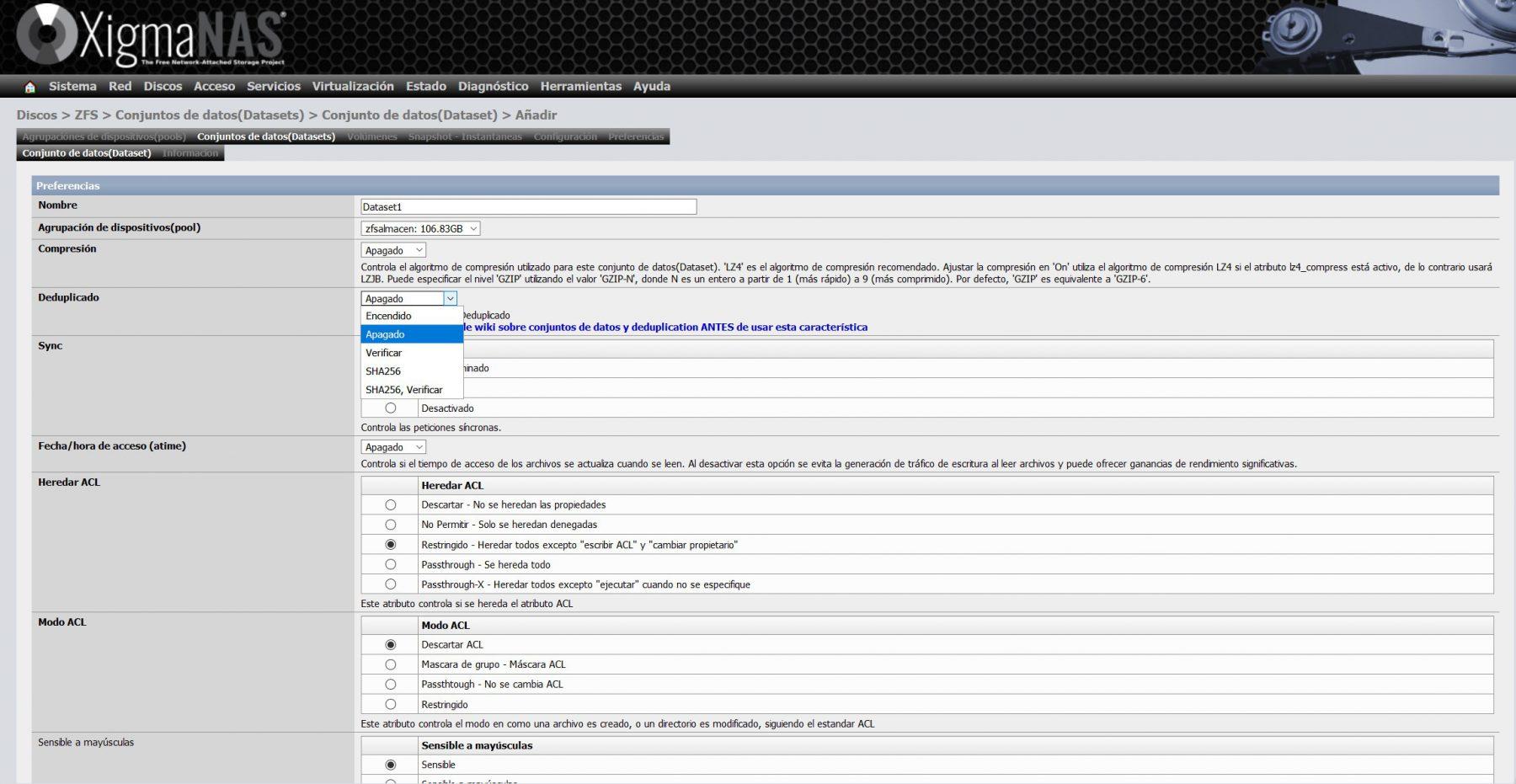
Il faut se rappeler que, si on sélectionne l’option déduplication, cela va consommer une grande quantité de RAM, XigmaNAS lui-même nous en prévient sur son wiki.
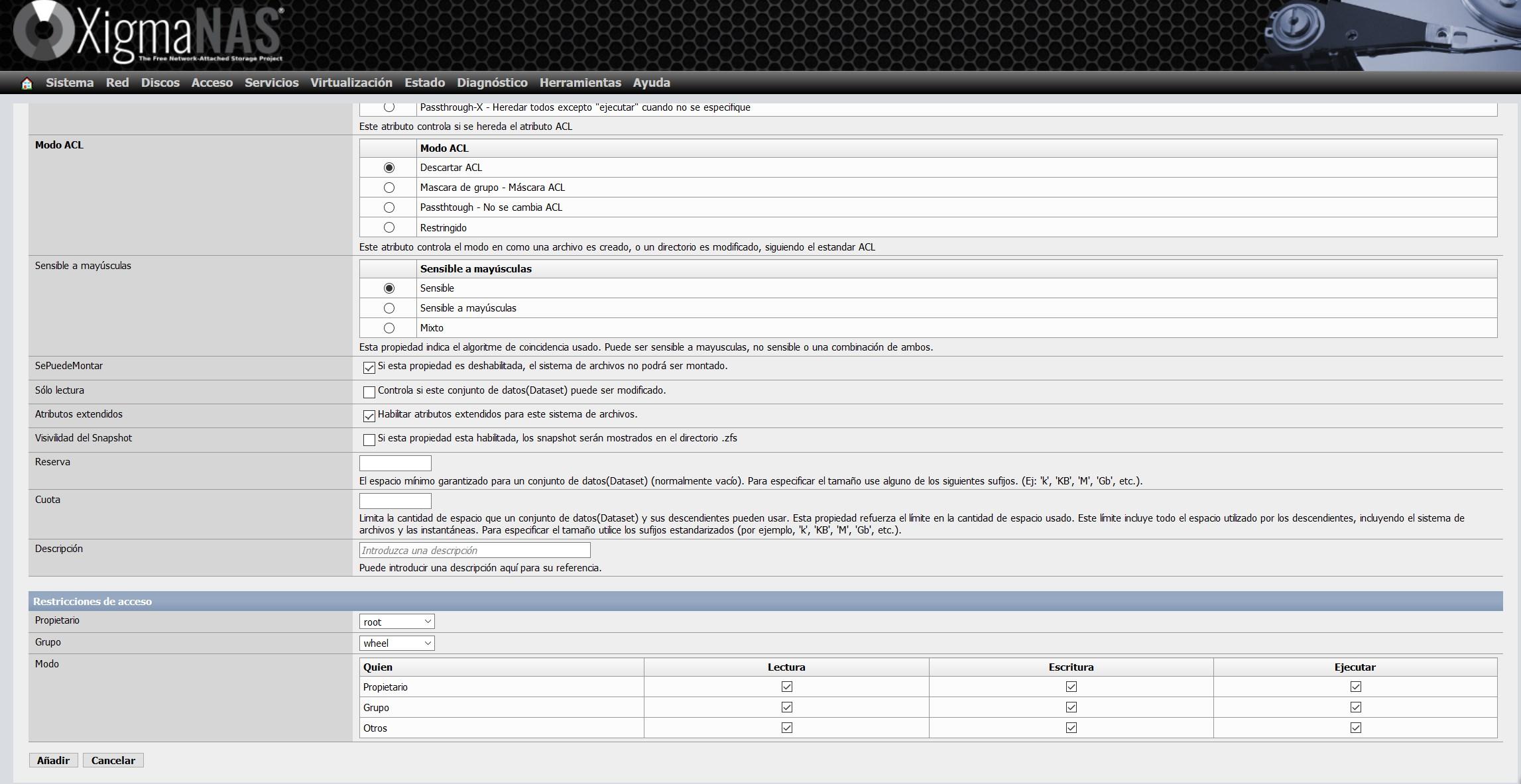
Les autres options de configuration disponibles sont les suivantes :
Une fois le jeu de données créé, il apparaîtra ainsi au sein du pool « zfsalmacen » que nous avons créé précédemment.

Nous ne devons pas oublier que nous pouvons également créer des périphériques de bloc, les soi-disant volumes dans ZFS :

Autres options ZFS
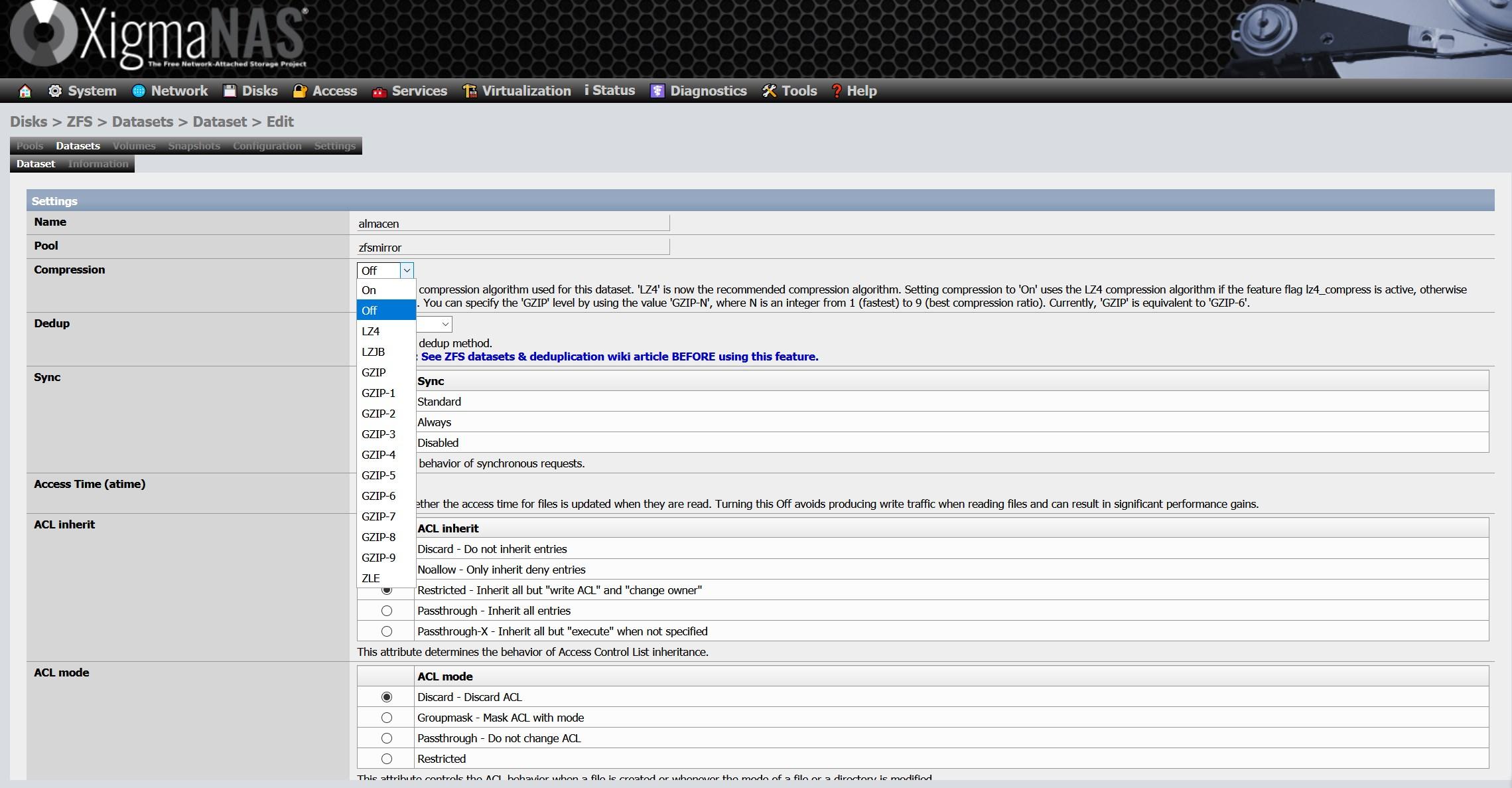
Les autres options disponibles sont les instantanés ou les instantanés, nous pouvons créer des millions d’instantanés, programmés ou manuellement. Pour configurer un snapshot, il suffit de cliquer sur le «+» pour en ajouter un nouveau :
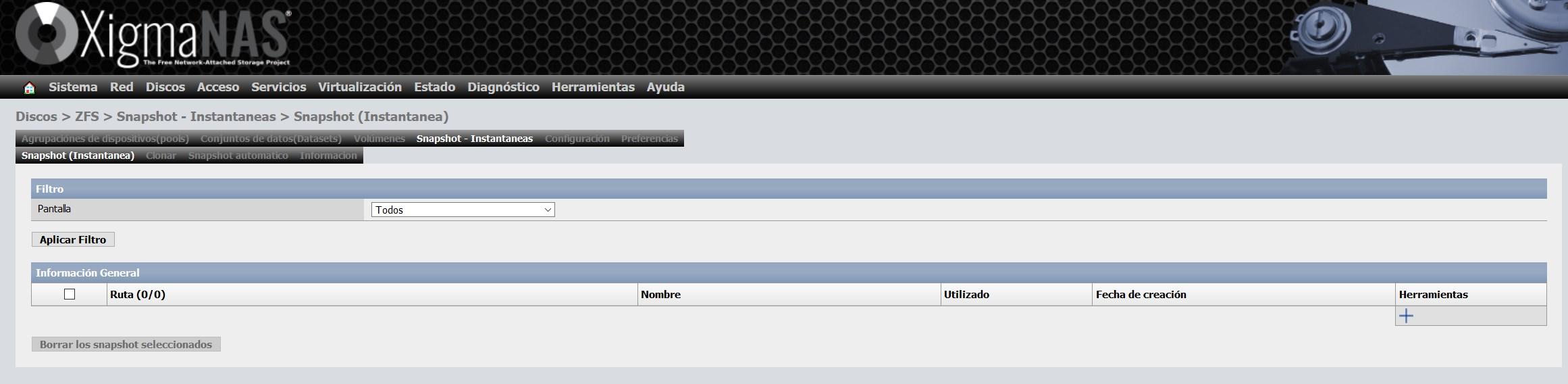
Nous sélectionnons ce que nous voulons prendre un instantané, nous pouvons le faire à l’ensemble du pool, ou uniquement à un ou plusieurs ensembles de données que nous avons dans le pool :
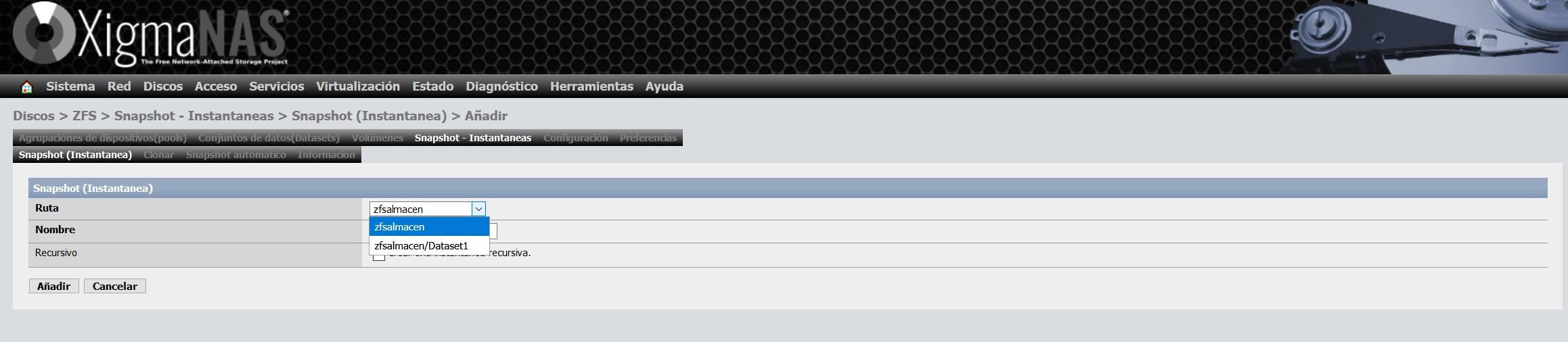
Une fois l’instantané créé, nous verrons quelque chose comme ceci :
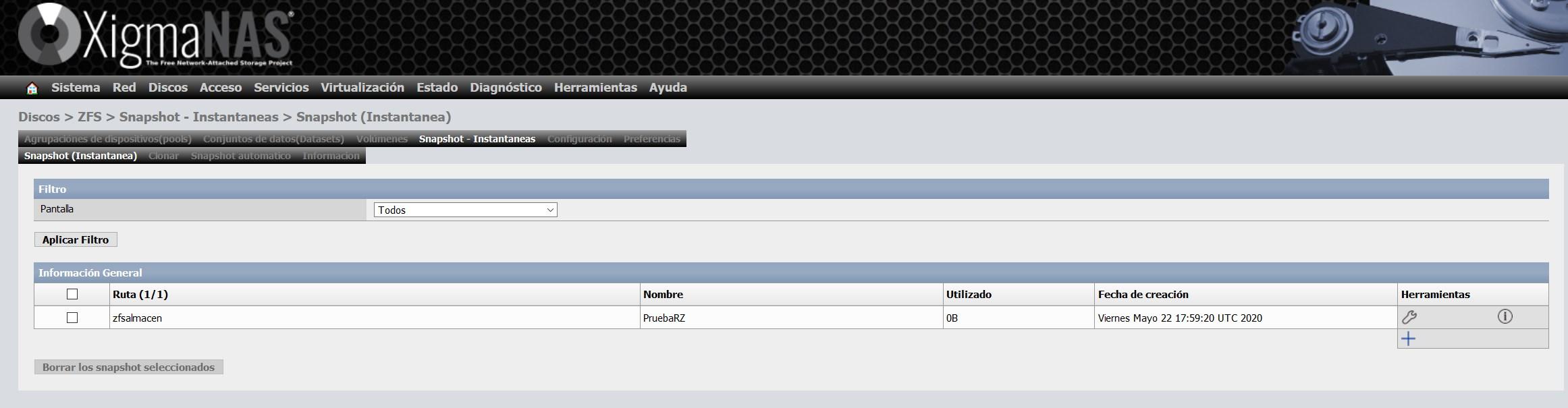
La plus importante est la colonne «utilisé», car c’est l’espace qu’occupe cet instantané, et c’est parce que des modifications ont été apportées ou des données ont été supprimées. Étant donné que les instantanés sont natifs de ZFS, l’efficacité est vraiment impressionnante.
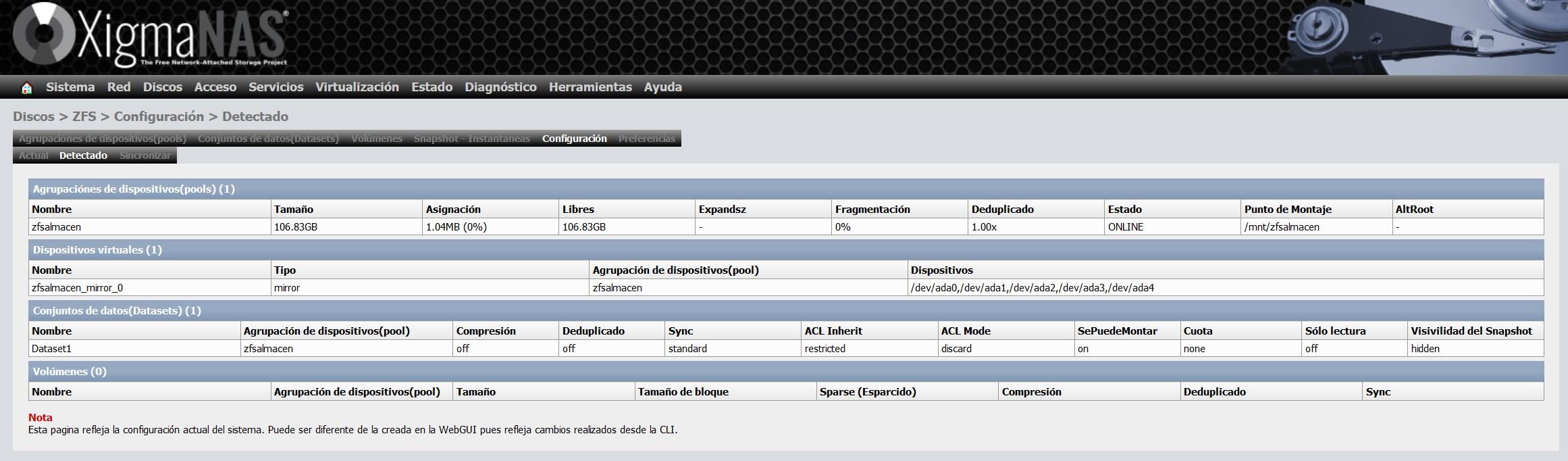
Dans la section «Configuration», nous aurons un résumé de tout ce que nous avons configuré jusqu’à présent, nous pourrons voir les périphériques virtuels, les pools, ainsi que les ensembles de données et les volumes créés.
Dans le menu principal du système d’exploitation, nous pouvons voir que nous avons le pool «zfsalmacen», et il indiquera l’espace total, occupé et disponible.
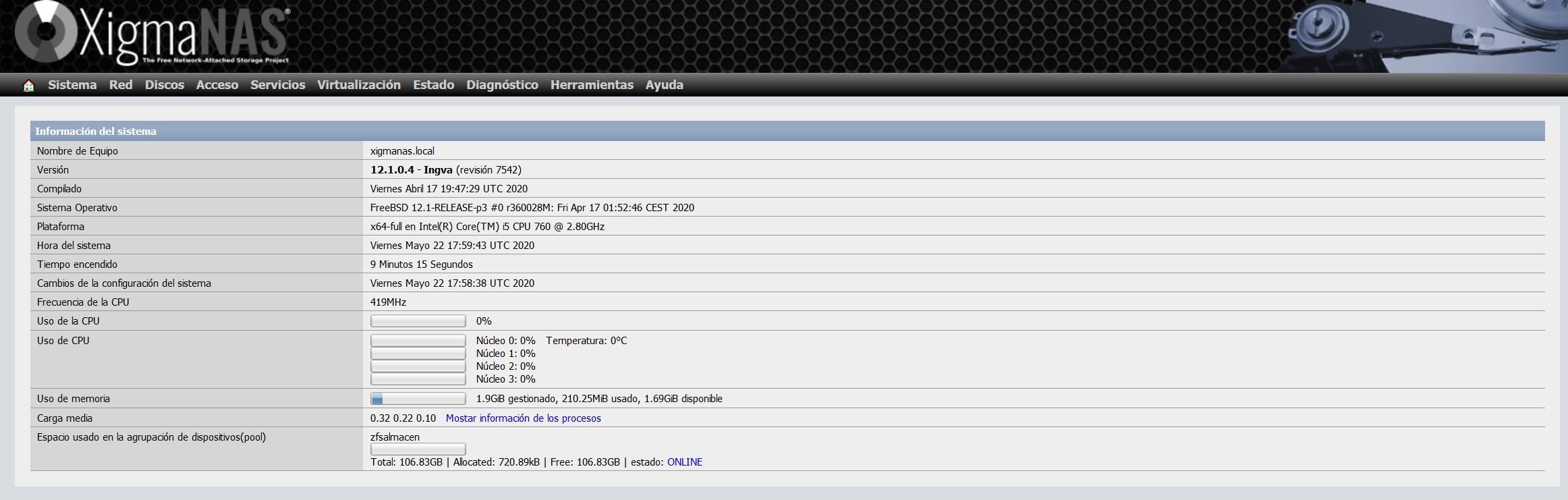
Comme vous l’avez vu, ZFS est un système de fichiers très avancé et nous permet une grande configurabilité. En cas de panne de disque, mettez-le simplement hors ligne, ajoutez-en un nouveau, ajoutez-le au pool et effectuez un nettoyage pour examiner l’ensemble du pool et régénérer les données.
Configuration et démarrage de ZFS sur Debian et autres
Bien que ZFS soit un système de fichiers avancé, en raison de certains problèmes avec la licence pour l’utiliser, de nombreuses distributions Linux ne le prennent pas en charge par défaut , de sorte que le démarrage peut être quelque peu fastidieux sur de nombreux systèmes lorsqu’il faut installer et configurer les fichiers système manuellement.
Si nous voulons utiliser ce système de fichiers dans notre système d’exploitation, nous pouvons le télécharger gratuitement à partir de son site Web principal . De plus, les principaux référentiels ont également des packages précompilés, donc, par exemple, si nous voulons l’installer dans Ubuntu, nous n’avons qu’à le télécharger à partir des référentiels officiels avec apt qui, avec le reste des packages nécessaires, seront installés entièrement automatiquement.
sudo apt install zfs
Lors de la gestion des disques, ce système de fichiers utilise le concept de « pool ». Un pool ZFS peut être constitué d’un ou plusieurs disques durs physiques. Par exemple, si nous avons 3 disques durs et que nous voulons profiter de leur capacité en tant que single ( stripe



